





上期说到,在法律文书生成的场景中,法律专业大模型的表现要优于通用大模型:通用大模型 VS 法律专业大模型——谁更会写答辩状?六大陷阱实测
本期我们来继续看看法律大模型成在类案检索这种具有复合性的任务中,是否还有着更好的表现。
本文共2958字, 阅读时间约为15分钟。
Part 1 Intro
开篇我们不妨再讨论一下法律大模型在法律任务处理上的一些优点。一般来说,法律大模型从整体上来看有两个先发优势:
1、使用高质量法律数据进行微调(SFT)
自年初幻方量化DeepSeek的“平地一声惊雷”,诸如MoE门控机制、GRPO强化学习策略及长思维链数据(Long-CoT Data)微调等大模型SOTA技术概念登台亮相,模型技术迭代的讨论也不再局限于AI专属的圈子里。特别是长思维链推理能力的R1模型,很大程度上让公众开始对AI大模型有了新的认知。
而对于专攻于法律垂类的专家模型——法律大模型而言,微调等阶段会更侧重于使用优质的法律数据以提升法律任务处理的准确度。对于推理侧的能力,如使用专业领域相关的思维链数据进行训练,也更能够拟合一般意义上法律实务人员的思考方式。
2、动态知识的支持
尽管微调对模型而言很重要,但是仅靠微调内化的法律词元参数乃至思维链,遇上具体的法律问题,还是可能出现幻觉的。甚至有的时候,开启了深度思考能力的推理模型也还是会出现文不对题的回答。
这是因为,一来通用大模型知识对人类各类词元只有着过于广泛、模糊的“记忆”,在哪怕是在微调过程中特地涵盖到了某一专业领域的训练语料,有时候大模型在面临具体的问题(比如专利法中药品专利期限补偿相关的制度及其适用),也可能会有“失忆”和“编造”的风险。
然而,即便是诸如法源寻找和法律适用这种基础法律任务,对模型输出的知识都有着准确性和严谨性的最低要求,遑论法律问题研究、类案检索报告以及各类文书生成之类的高级任务;二是法律数据往往是具有一定时效性。比如,一部法规可能会因为新的决定颁布而归于失效。
因此,基于检索增强(RAG)技术的知识库框架,就对模型回答法律问题的准确度提供了重要的印证支持。通过各种向量检索范式提取出来的具体目标文本,通过融入大模型的提示词的方式,给大模型这个“大脑”加上“海马体”,能够瞬时缓解模型在特定回答上可能出现的正确性和时效性谬误。在个性化检索增强的场景中,用户还可以把办案沉淀下来的本地语料上传到知识库中,作为模型回答的重要参考。
以小理AI为例,作为确保法律AI问答准确性和及时性的重要引擎,得理法搜中的案例和法规数据会在特定的问答场景中赋能法律大模型的输出,确保用户在相关的问答中始终有真实、实时的法律数据作为依据。
话不多说,我们进入的让测评环节。
PART 2 模型测评
(一)测评模型
本次测评中,通用大模型我们选取了原生的DeepSeek R1,以及近期推出的Doubao-1.5-pro-32k、文心X1这两个更晚发布且推理成本更低的模型与小理AI法律大模型进行对比。另外,为测试长思维链能力,所有的模型都已开启深度思考。
(二)测评维度
1. 案例相关:类案检索的关键在于案情事实的相似和裁判意见的比对。因此,模型要能初步胜任类案检索总结工作,充分条件之一是在提供案例相关度上有基本保障。同时,如基本事实部分存在较大差异的类案,模型最好能做到予以剔除。另外,鉴于大模型幻觉的特性,案例的真实性也需要认真考察。
2. 信息对齐:大模型具备上下文提取和总结的能力。而对案例原文上下文的提取和总结能具备一定的精确度(尤其是关键事实和法院认为的部分),也是模型初步胜任类案检索总结工作的另一充分条件。毕竟,如果某一事实或者判决说理要素被模型理解成其他义项,提炼结果的偏差会增加复核带来的时间成本甚至是信赖成本。
3. 效力明确:参考最高院去年五月颁布的《人民法院案例库建设运行工作规程》(法〔2024〕92号)中的规定,人民法院审理案件时,参考入库类似案例作出裁判。入库的文书不论是指导性案例还是参考案例,都对类案研究具有较高的参考示范价值,其中指导性案例优先级更高。
而对于普通裁判文书来说,上级法院的案例的参考性则优于本级法院的案例。如果模型能够“读懂”效力遴选的指令的意图,将会为用户节省较多的挑选时间,生成一份完整度更高的类案检索总结。非终审的案例,在这个环节最好也要予以排除。
4. 呈现合理:整体结构要贴近于一份完成度较高的类案检索总结/报告。结果报告末尾需附上案例和对应案号及适用法律法规(如可以超链方式跳转相关类案/法规全文页供使用者复核,则更佳)
PART 3 测评问题
我们以一个劳动争议相关的类案检索任务作为测评问题,并将以上类案检索要求融合进提示词里,看看三个通用大模型和小理AI法律大模型是否能很好的消化这些需求。
Prompt:
“请你针对争议焦点“年终奖发放前离职的劳动者,是否有权主张用人单位支付年终奖”检索案例,并生成一份案例检索总结。检索总结的要求如下:1.比对我方案件事实:劳动者在年终奖发放之前被裁,用人单位根据其制度不予支付年终奖。2.体例为[检索结论][类案情况][适用规范]以及[类案情况]部分请仔细对比基本事实和法院认为部分。3.参考优先级别需按照指导性案例>参考案例>普通案例的顺序排布。”
PART 4 结果
1、通用大模型
(1)DeepSeek-R1


✦
滑动查看完整回答
✦
(2)文心X1



✦
滑动查看完整回答
✦
(3)豆包-1.5-pro-32k


✦
滑动查看完整回答
✦
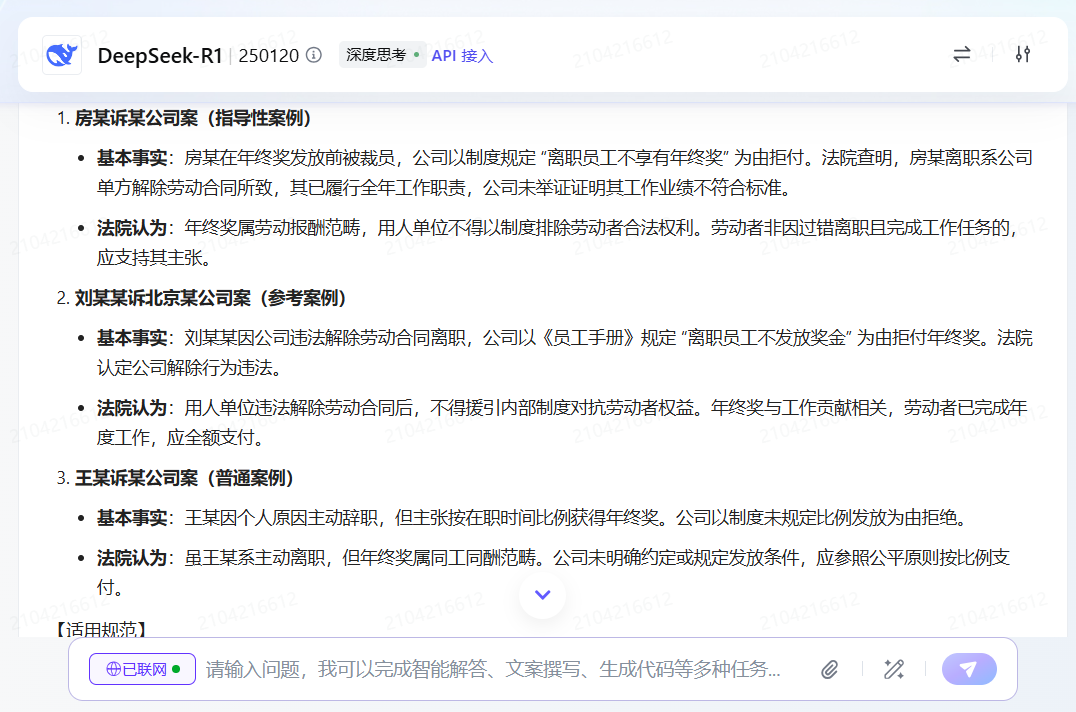
对于三个通用大模型而言,或许是因为开了联网模式,或在预训练过程中曾经“见过”相关数据的原因,其类案都返回了最高院指导案例183号房某诉某寿险公司这一较为知名的指导案例。
另外,三个模型也都基本能理解并遵循案例优先级排序和生成体例的指令,按照三分化的结构编排了检索结果和总结。
欠缺的方面则比较显而易见,在案例相关性方面,由于都开启了联网模式,DeepSeek-R1和豆包-pro-1.5-32k,除了指导案例183号外,各个模型或多或少通过搜索引擎都获取到了一些其他级别案例的片段信息,其中豆包-pro-1.5-32k也返回了(2019)京 01 民终 10336 号这一真实案例,但是大多数模型并没有标明案号等案例的出处以备查验。文心X1这边,则是除了指导案例183号之外没有提供其他的类案。
在信息对齐维度上,DeepSeek-R1没有体现出按照用户指令将用户所提供的基本事实描述与返回的案例进行对比,似乎在指令上有所遗漏。同时,在该模型返回的刘某某诉北京某公司案的法院认为部分,将“公司依据《员工手册》的规定不予发放年终奖金不合理”转义为“不得用《员工手册》对抗劳动者权益”描述略有不当。豆包这边,则是对联网搜集的网页结果出现了幻觉,“湖北武汉叶女士案”这新闻报道事件当做真实的司法案例加入了回答中,可信度打了折扣。
2、法律大模型
(1)小理AI





✦
滑动查看完整回答
✦
小理AI这边,案例相关性方面,可以看到小理基于一个指导性案例(183号)、一个参考案例以及两个普通案例返回了案例检索结果,且在第一部分“检索结论”部分以及第二部分“类案情况”里面,按照用户指令将其指定的基本事实和类案的基本事实进行了比对,而且案例也按照参考优先级进行了排序。在结论中,也归纳了法院在判断用人单位是否应当支付年终奖的一般司法倾向。另外,如果在没有提示词的情况下,小理也能够识别应当选取终审案例的潜在意图,则更佳。
信息对齐维度方面,小理使用了真实的案例数据进行知识抽取提炼,因此相应的基本事实与法院认为部分基本都能还原裁判文书的对应部分。每个案例对应的案号也生成在了类案详情的段落中,相应的案例超链也附在了大模型生成内容的下方,以备用户随时查询案例全文。
PART 4 结语
从禀赋上来看,相比通用大模型,法律大模型更能胜任案例检索总结这种法律任务的处理。通用大模型无论是囿于过于广泛的语料还是缺乏动态性的“硬伤”,在泛化的场景中可能表现较好,但在法律问题的处理上始终有些许“隔靴搔痒”的感觉,而得理法律大模型在微调和知识库增强的优化下,能够比较好的解决知识正确和知识更新的问题,从问题的根本上缓解大模型所产生的幻觉。
法律大模型 + 法律大数据 + Deepseek
全新小理AI免费试用
一键开启智能化法律之旅
WEB端进入小理AI首页
https://www.delilegal.com/ai
小程序端点击得理法搜立即跳转
扫码下载得理律助/法搜app立即体验


得理律助APP
得理法搜APP
-End-


