





Deepseek爆火强势引领全民迈入大模型时代。在这股技术浪潮之下,法律行业也积极探索运用Deepseek来完成各类法律任务。此前得理策划了《Deepseek与法律专业大模型深度拆解系列》剖析了Deepseek于法律研究、案例检索总结、合同生成、法律文书等场景中的应用。
全新《通用大模型VS法律专业大模型系列》将对Deepseek-R1和其他主流通用大模型进行测评,看看通用大模型与法律专业大模型在法律问题的处理上表现如何。
本文共4327字, 阅读时间约为14分钟。
本期我们将通过一个法律研究实例,比对通用大模型和专业大模型的表现并进行点评,看看法律大模型是否还有着更好的表现。
* 本系列前两期文章,请点击查看《通用大模型VS法律专业大模型系列》
本次测评目的在于观察通用大模型与法律大模型在法律研究场景解决问题的不同表现,考察不同大模型在法律研究场景下的语言理解、内容生成、知识问答和逻辑推理能力,因此,衡量精准程度的F1、衡量时间特性的首字响应时间、处理效率和并发路数的指标不在考察范围,本次测评主要从衡量输出信息综合效能的正确性、完整性、相关性和有效性四个维度来评判大模型生成的内容。
正确性
衡量大模型在法律研究中表现的首要指标。它表征大模型生成内容真实正确的程度。
完整性
模型的输出涵盖回答法律问题所需所有必要信息的程度。它确保没有遗漏关键法律要点。
相关性
模型输出与用户输入或法律任务的相关性。
有效性
模型的输出对用户的有用性和清晰度。
具体评分标准如下:
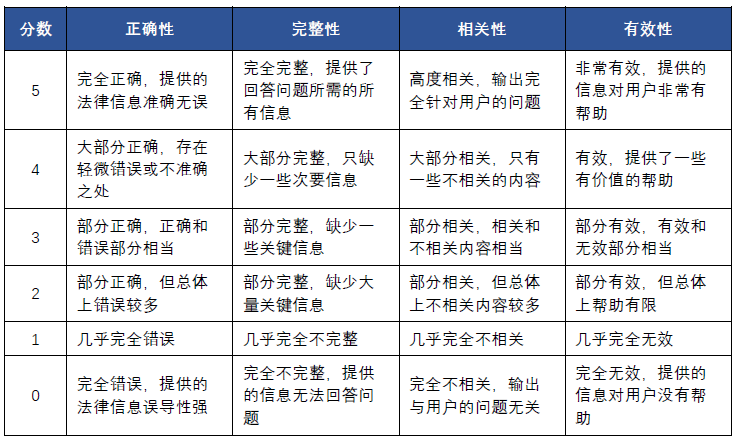
评分计算方式:Q = (s1+s2+s3+s4)/(4×5),其中s1、s2、s3、s4分别为正确性、完整性、相关性和有效性。
QUERY
因限定法律研究场景,所以测试用例语言风格均为法言法语,文本相对较长,偏学术研究。
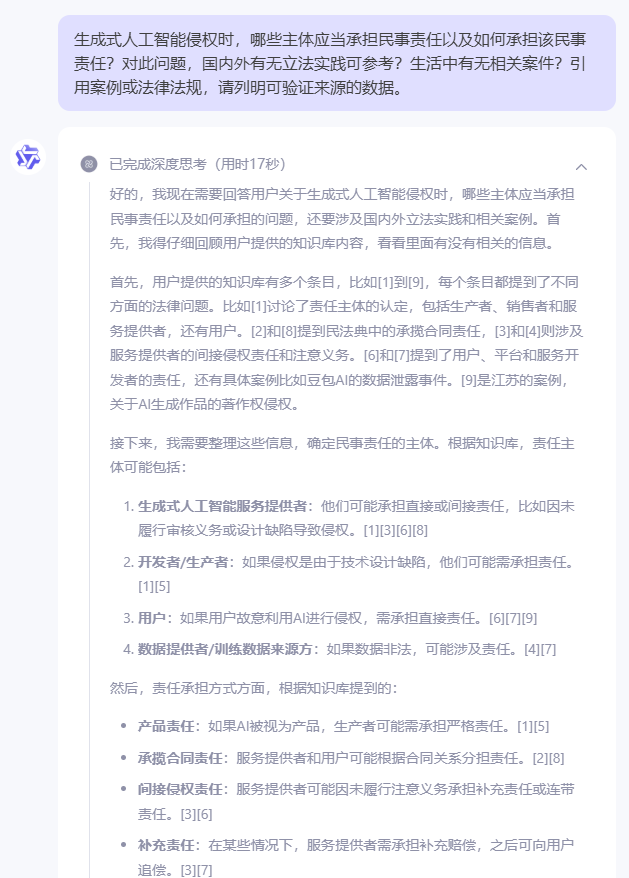
生成式人工智能侵权时,哪些主体应当承担民事责任以及如何承担该民事责任?对此问题,国内外有无立法实践可参考?生活中有无相关案件?引用案例或法律法规,请列明可验证来源的数据。
测试结果分析及评分
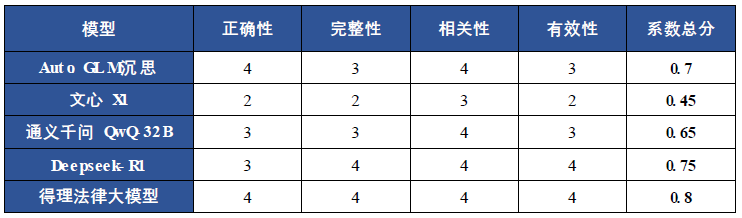
本次参与测评的通用大模型为Auto GLM沉思、文心一言X1、Deepseek-R1、通义千问QwQ-32B,法律专业大模型为得理法律大模型。
# 1
Auto GLM沉思
AutoGLM沉思是智谱团队于2025年3月31日推出的一个能探究开放式问题,并根据结果执行操作的自主智能体(AI Agent)。 它能够模拟人类的思维过程,完成从数据检索、分析到生成报告。
下图为AutoGLM沉思自己利用chrome浏览器执行搜索的页面截图。
✦
左右滑动查看
✦
AutoGLM沉思生成结果如下:
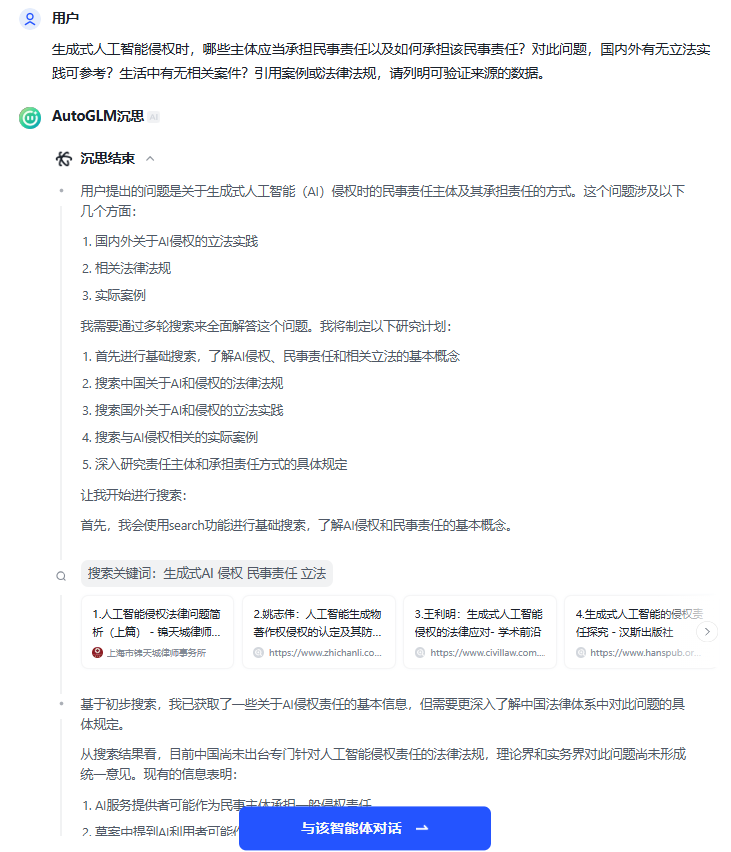

















✦
滑动查看完整回答
✦
1)正确性:4分
从其沉思过程来看,“chat GLM沉思”能够准确识别用户意图,制定周密的研究计划(基础概念--国内法律法规--域外立法实践--相关主题案例-责任主体和责任承担的规定),通过执行多轮搜索生成一份研究报告。
但值得注意的是,基于前期搜索得出法律专业人活跃于知乎的结论,它在查找案例时首先考虑去知乎寻找案例佐证论点,这一点不太符合法律人对于引证案例准确性性的要求。
观点生成方面,引用了多位学者的观点,但在论证责任主体认定的AI利用者这一段时,“根据相关草案”指向的是《人工智能生成物著作权侵权的认定及其防范——以全球首例生成式AI服务侵权判决为中心》文章中提及的域外立法实践,即日本文化审议会著作权分科会法制度小委员会制定的《人工智能与著作权处理方案(草案)》,属于转引。
在论证国外立法实践时,在举例欧盟和美国立法实践后,将美国某高校学者观点和欧盟机器人民事法律规则归为“其他国家立法实践”,归类错误。且域外立法实践均为转引用来源。
在论述国外司法实践中的生成式人工智能侵权案例中的“其他国家的AI侵权案例”,将我国首次判决保护AI使用者著作权中提及的Stable Diffusion当作英国案例予以论证,将某篇知乎文章提及的纽约时报诉OpenAI案字段理解为荷兰的侵权案例,存在错误。
因此扣分。
2)完整性:3分
虽然研究计划周密,但囿于各资源网站平台的账户门槛,如搜索知乎、知网时需要人工辅助登录账户,没有知识库支持的前提下,研究所能使用的资源有限;国内立法仅仅引用《民法典》第1194条关于网络侵权责任之规定、第1195条关于网络服务提供者侵权补救措施与责任承担之规定;引证案例为知乎上搜到的全国首例“AI声音侵权案”、生成式AI服务侵犯奥特曼著作权案和AI生成图片著作权侵权案;域外立法实践进行了转引举例;国内外司法实践予以陈述;最后对责任主体认定标准、责任承担方式进行阐释,甚至提出了相应主题的立法论建议。信息偶有错误(幻觉),论述层次略有混乱(责任认定和责任承担首尾均有论述、域外立法实践中提及案例和学者观点),要素齐全到用户会觉得有信息堆砌、重复之嫌。因此扣分。
3)相关性:4分
输出结果的思路与用户提完高度相关,但如前所述,模型幻觉导致部分信息无关,因此扣分。
4)有效性:3分
思维链部分内容提供了法律研究的清晰思路,但是具体执行过程中,它缺乏法律人的严谨,转引信息的正确性不可考证,对域外立法和司法实践的定义模糊不清,对国内立法的陈述内容过于单薄,整个研究报告的逻辑结构略有含混,因此扣分。
# 2
文心X1




✦
滑动查看完整回答
✦
1)正确性:2分
从其思维链来看,文心X1能够拆解用户需求并分类(国内外立法实践分析、相关案例分析、责任主体及责任承担方式并注重数据引用的可验证性)进行对应搜索。从而得出覆盖国内外立法框架、典型案例及责任划分逻辑,包括《民法典》条款、欧盟风险分级监管、美国避风港规则适用等关键细节的结论。
但值得注意的是,在论证责任主体与承担方式时,未列明其观点生成来源或依据,因此正确性存疑;在立法实践中,对民法典的原则阐释亦未能按要求具体到条文数;引用的《生成式人工智能服务管理办法》第5条来论证服务提供者责任的内容仅为征求意见稿,而非生效办法的内容,时效性存疑;关于域外立法动态和司法实践部分的论述,有理由相信模型是从搜索到的论文中获取的字段信息,但由于文心X1的引用格式限制,核验难度较大,与利用大模型省时省力提供可信结论的动机是背道而驰的,所以扣分。
2)完整性: 2分
思考逻辑完整,但是内容缺少大量关键信息,域外立法和实践信息存疑,因此扣分。
3)相关性:3分
输出内容形式上确实符合用户意图,但是内容单薄,引证不规范,因此扣分。
4)有效性:2分
从引证的规范性角度,文心X1提供的内容可参考意义不大,但从对问题的理解思考、推理逻辑来看,能对用户提供有限的帮助。
# 3
通义千问QwQ-32B





✦
滑动查看完整回答
✦
1)正确性:3分
从其思维链中,千问逻辑是清晰的,也能准确识别诉求并根据其向量库提供信息,确定了责任承担主体和方式。国内立法仅有《生成式人工智能服务管理暂行办法》和《民法典》以及《著作权法》相关内容,而域外立法方面论述略显薄弱;典型案例方面用“豆包AI用户信息泄露案”真实性存疑,该案例参考来源文章并未明确提及该案例为可公开查证的法院案例;在论述国外立法中根据来源文章中提及的欧盟《人工智能法案》(草案)和美国《侵权法重述》,均无法得出“要求开发者承担更高责任”“适用严格产品责任”的观点。因此扣分。
2)完整性:3分
对责任承担主体和责任承担类型予以论述,但未提及责任承担方式;立法引用较少且域外立法用以论证观点存在模型幻觉;案例不全。因此扣分。
3)相关性:4分
能够理解用户需求并分点论述,观点提供来源依据但存在错误;整体论述不够详尽。
4)有效性:3分
作为通用大模型,幻觉隐蔽,但根据域外立法总结的观点错误却有重大负面影响,且案例方面对豆包AI侵权案例的引用也不符合法律人的需求,因此帮助相较于其他模型而言是有限的。
# 4
Deepseek-R1

✦
上下滑动查看完整回答
✦
1)正确性:3分
从其思维链来看,能准确识别问题并根据搜索结果提取相关信息,从而形成其结构清晰(责任主体及承担方式-国内外立法实践-典型案例)、内容完备(有理有据、依据大部分可查)的结论。但在域外立法实践和案例论述部分,编造了一个无依据的美国Thaler案,论述欧盟《人工智能法案(草案)》相关内容时无依据,来源存疑。
因此扣分。
2)完整性:4分
对责任主体和承担方式的阐述比较完整,国内立法实践举例相对齐全,但未能全部覆盖;域外案例存在编造。
因此扣分。
3)相关性:4分
问题完全围绕用户意图展开研究,推理过程与用户输入高度相关。但是在内容输出方面存在噪音数据的干扰,存在少量不相关因素。
4)有效性:4分
在责任主体和承担方式方面提供了一些有价值的帮助,国内案例的选取也较为典型,但基于模型幻觉因素,案例有编造,因此扣分。
# 5
得理法律大模型



✦
滑动查看完整回答
✦
1)正确性:4分
从其思维链俩看,小理AI能厘清用户的诉求并据此形成结构清晰明了的搜索策略。
责任主体方面,引用的《网络数据安全管理条例》第19条直接说明了提供生成式AI服务的网络数据处理者的义务,同时引用《民法典》第1194条和司法解释用于论证网络用户、服务提供者以及信息处理者的主体责任;在责任承担方式方面,从向量库中引用了有完整案号的可验证案例予以论证;在论述责任主体的网络用户部分,虽然案例真实,但相关性不够精准;然而,值得欣喜的是,它最后根据司法解释还考虑到了举证责任的问题。这一点是优于通用大模型的。
2)完整性:4分
在国外立法实践方面,由于其知识库尚不涉及域外法律,因此略显薄弱。因此扣分。
3)相关性:4分
完全理解用户需求,并分点论述,有理有据,输出内容跟与用户要求高度相关。但部分案例相关性不够。
4)有效性:4分
作为法律大模型,小理AI能提供大量权威、可验证的法律法规司法解释以及案例资源,专业性强,在法律研究场景能够满足用户的绝大部分需求,不仅能提供价值较大的帮助,还能提出相关的法律知识点(举证责任)。
评分汇总
* 想要详细了解通用大模型与法律专业大模型差异如何产生,请点击查看《Deepseek爆火背后——通用大模型与法律专业大模型有何差异?》
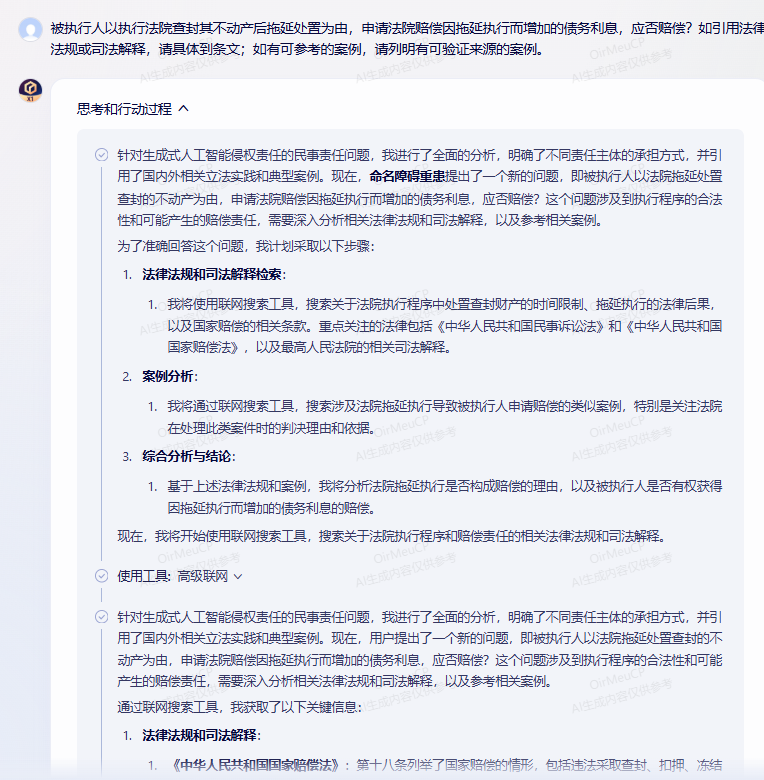
从人工智能侵权责任问题的研究表现来看,通用大模型和法律大模型在理解用户意图、进行逻辑推理、生成相关内容方面的综合性能各有所长。从完整性来看,通用大模型开启了联网模式,在开源推理模型的基础上进行了知识库增强的优化,因此各家表现相对理想。但从准确性、相关性来看,通用大模型尽管开启了联网搜索,但是法律行业数据空间的专业壁垒始终高耸。
在测评另一法律问题时,笔者观察到AutoGLM沉思试图通过Chrome浏览器打开裁判文书网进行案例的查询,未果;打开知网查询论文仅能看到标题,期刊内容亦无法识别。有着指挥自身行动和工具调用的AI Agent尚且如此,更别提其他通用大模型在这一方面的短板了。虽然大模型幻觉各家或多或少依旧存在,但从有效性而言,在经过微调和法律专业知识库增强优化下的法律大模型更能胜任法律问题的研究。


法律大模型 + 法律大数据 + Deepseek
全新小理AI免费试用
一键开启智能化法律之旅
WEB端进入小理AI首页
https://www.delilegal.com/ai
小程序端点击得理法搜立即跳转
扫码下载得理律助/法搜app立即体验


得理律助APP
得理法搜APP
-End-


