





12月4日,“AI+法律”服务助力企业高质量发展专场活动圆满结束,中科院深圳先进院-得理法律人工智能实验室主任杨敏博士受邀进行主题分享。
杨敏博士带来了“法律大模型前沿技术”的主题分享,介绍了大模型驱动的个体智能及群体智能相关内容,并详细介绍了首个基于大模型多智能体的法庭模拟系统 AgentCourt。
以下为主题分享内容,经过编辑整理。
法律大模型的诞生,展现出了AI在法律领域的创新应用和广阔前景,为人机融合和交互,AI法律协同之路提供了新路径与新灵感。
基于大模型的单体智能
大模型是基于神经网络架构的模型,参数处于10亿到万亿级别,能深入捕获语法、语义以及上下文的关系,从而生成高质量的自然语言回复。
基于大模型的单智能体是依托大语言模型构建的智能系统,以单一角色独立执行各类任务。这种智能体,通常整合了记忆规划及工具使用等多种功能可为用户提供智能化和全方位的服务。在智能体中,大模型以核心大脑的角色存在。
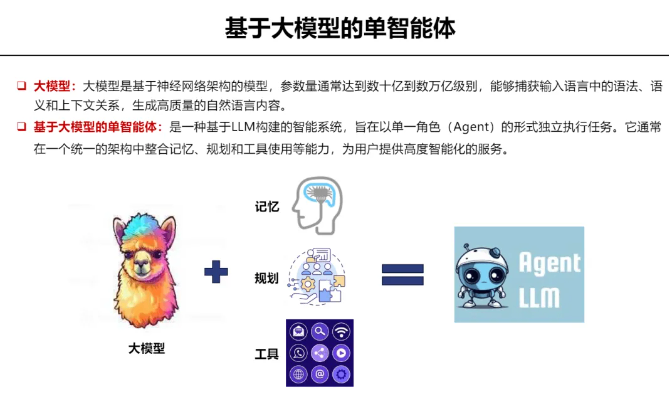
智能体的功能依赖于以下三个核心点:
01
规划
智能体相对于大模型,具有一定的规划能力,可将复杂任务分解为简单子任务,并按照一定步骤来执行任务。同时进行相关思考,然后判断是否需要继续执行任务或者说判断任务是否完成来终止运行。
02
记忆
智能体拥有短期记忆和长期记忆。
短期记忆:在执行特定任务的过程中使用的,可暂存上下文信息。待任务完成后,暂存的信息就会清空。
长期记忆:通常存储在外部知识库中,以项链数据库形式进行存储、检索,能够长期保留的。
03
工具使用
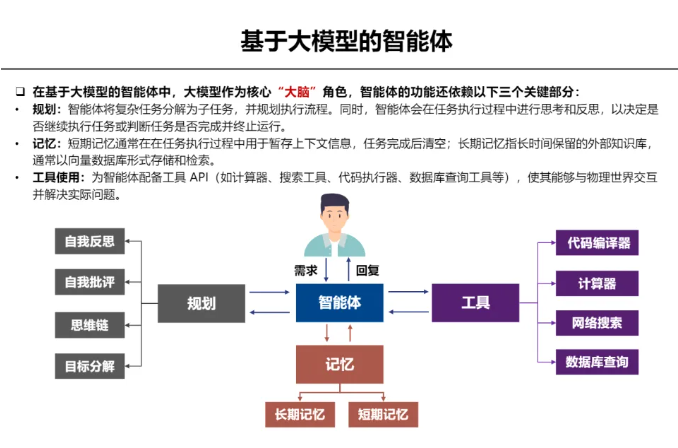
大模型并非万能,其功能是有限的。
比如,大语言模型本身是生成模型,并不具备检索功能。如果想用大语言模型进行检索就需要调用外部的工具,为智能体配备工具 API(如计算器、搜索工具、代码执行器、数据库查询工具等),使其能够与物理世界交互并解决实际问题。
此外,大模型在数学计算方面能力也是有限的。有些时候大模型甚至无法分辨10、10.9、10.11 的数值大小。所以,在进行比较复杂的数值运算时,大模型通常需要调用外部数据而不是依赖其本身。
从单体智能到群体智能
群体智能是由单体智能进行组织协同而产生的。
01
智能个体关键要素
记忆、规划、工具、语言、环境
02
智能群体关键要素
目标、组织、关系、路由
单体大模型缺乏一定的记忆和协调能力,无法直接处理复杂任务。
从个体视角来看,大模型聚焦于内容生成,但缺乏记忆系统和环境感知能力
从群体视角来看,大模型可被视为独立个体,但不具备组织结构和群体协作能力。
目前基础模型聚焦于提升单体模型的能力,未来智能系统整体效能的提升应在于构建人类与机器、机器与机器、机器与环境的协同融合及交互体系,推动从单体智能向群体智能的飞跃。

AgentCourt是全球首个基于多智能体的法庭模拟系统。在一周之内可以完成1000场案件的处理,为法律实践提供了全新的思路和方向。
*更多关于 AgentCourt 的资讯请点击:
首个AI法庭AgentCourt:一周打完1000场官司,中科院深圳先进院-得理法律人工智能联合实验室发布
该系统操作简单,只需要输入案情描述或是上传起诉状、答辩状,律师智能体便可以根据案情模拟真实的庭审,对提交材料进行答辩。
在模拟过程中,基于大语言模型的律师智能体能不断优化和进化,在部分任务中的表现已经超越了人类律师的能力。
多智能体角色分工
法庭模拟系统中设定了六个角色。
01
原告、被告 智能体
一旦产生纠纷,将自动寻求律师事务所的法律援助,原告或被告在与律师的互动中可以直接获得诉状或答辩状,无需从头起草。
02
原、被告代理律师 智能体
最重要的角色,在对抗辩论过程中不断进化,拥有收集案件信息、分析证据并按照法庭程序进行辩论的功能。
03
法官 智能体
负责监督整个法庭的过程,总结两个律师智能体的论点,提出问题并做出最终判决。
04
法律数据源 智能体
主要负责宣布审判的开始和庭审纪律等,会详细记录整个审判的过程,类似法官助理和书记员的角色。
这些智能体在法庭中相互配合,从而让多智能体可以协作和对抗。
前期数据准备
法庭模拟系统的数据来源于中国裁判文书网的10000个民事判决案件。经过数据清洗和筛选,其中1000个具有代表性的案件被挑选由律师进行数据净化,最后产生了用于模拟法庭训练和测试的第一版数据。
在后续版本当中,模拟法庭数据量量级将不断提升。
用于训练的案例文件由大模型进行了匿名化的处理,确保数据在保证真实性的同时不泄露隐私。
法庭模拟流程
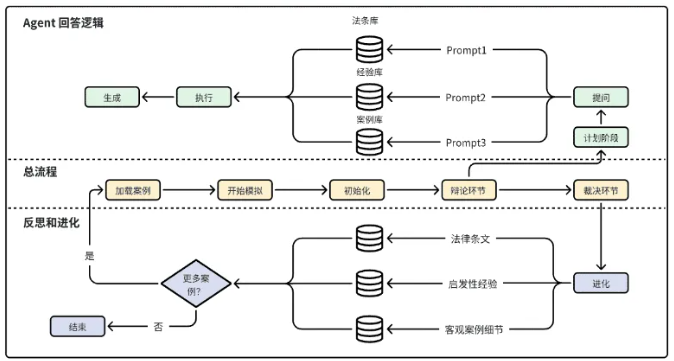
在法庭模拟的过程中,双方律师基于真实的案例的起诉状和答辩状展开辩论。在庭审过程中,多个智能体通过协作完成整个庭审的过程。
通过对抗性的辩论过程,律师智能体可以不断进化、不断反思,向对手学习。
两个律师智能体的对抗性进化方法,主要包含了三个关键点:
01
法条记忆的塑造
法条记忆的塑造主要是提升律师智能体对相关法律条文的记忆和应用能力。包括直接提取以及反思生成。
直接提取:对庭审程序中出现的条款进行自动识别和存储,以便下次辩论时使用。
反思发现:智能体会自我反思发现未明确提及但与案件相关的法条,如:案涉案件我为什么胜诉?我为什么败诉?可以向对手学习到什么?通过不断自我反思,智能体可以补充没有被明确提及但与案件相关的法条。
02
经验库的扩展
自我反思过程: 每次庭审结束后,律师智能体根据法官智能体的最终判决进行自我反思,分析庭审中的表现,总结经验。
对抗性学习:智能体会积极学习对手在辩论过程中的有效策略,尤其会识别和掌握对方在辩论过程中提出的一些关键论点,逐步扩充律师智能体的经验库。
03
案例知识库的构建
案例知识库需要对每个案例进行提炼,提炼内容包括核心法律问题、关键证据点、决定性推理链、标志性决定等。
知识库可以不断丰富和完善律师智能体的案例学习经验,以增强律师智能体对类似案件的处理能力。
多智能体性能评估

现有的、没有进化的、比较静态的或称为非法律专业性的大模型的性能是有限的。
如上图未进化前的回答,大模型虽然已经进行了一些专业性的处理,但表现仍旧不如经过训练和进化之后的大模型般谨慎全面、能够考虑不同情况可能产生的影响。
同时,大模型模拟律师的学习过程类似于法学生从最开始仅有初级经验和水平,但在工作中和学习中不断进化,不断学习积累经验,最后升级打怪成长为一名专业的执业律师。
-END-


